Entropy and Language Models¶
Entropy is directly related to how large language models operate, and understanding it precisely is the foundation of everything the Entropy-Gated AI Framework does. Within this framework, entropy is treated as a concrete engineering constraint — the same way a systems engineer treats thermal load or memory pressure. It is not a metaphor. It is a measurable property of probabilistic systems that, when left ungoverned, degrades every outcome it touches.
Large language models are probabilistic generative systems. At each token generation step, the model produces a probability distribution over its vocabulary, conditioned on prior context. Sampling from this distribution introduces uncertainty — an unavoidable and measurable property of how these systems work. The framework is built around a single insight: that uncertainty cannot be eliminated, but it can be governed. Everything in EGAF follows from that.
Formal relationship (information theory)¶
In information theory, entropy measures uncertainty in a probability distribution by capturing how dispersed probability mass is across possible outcomes (Shannon, 1948).
For language models:
- Each token generation produces a probability distribution over candidate next tokens.
- High entropy corresponds to flatter distributions where many tokens are plausible.
- Low entropy corresponds to sharper distributions dominated by one or few likely tokens.
Formally, token-level entropy is defined as:
H = − Σ p(token) · log p(token)
Because language models rely on probabilistic sampling, entropy is never zero during normal operation. A true zero-entropy state would require deterministic decoding that collapses the distribution entirely, eliminating generative flexibility. Variability between runs is therefore a structural property of probabilistic language models — not a bug, not a limitation to be patched, but a fundamental characteristic to be governed.
This has a direct practical consequence: identical inputs can produce different outputs across runs. Systems that treat AI as deterministic will encounter failures that appear random. Systems built on this framework treat variability as a known quantity and govern around it deliberately.
Practical relationship (operator experience)¶
From the ROLE_USER perspective, entropy manifests as variability, drift, and inconsistency across interactions. Even identical instructions may yield divergent results due to contextual changes or accumulated stochastic effects.
Common observable consequences include:
- variation between runs with similar inputs
- sensitivity to phrasing, ordering, and formatting
- gradual drift across extended Lab sessions
- inconsistent reasoning chains
- compounding uncertainty across multi-turn exchanges
Entropy accumulation typically results from:
- unverified assumptions carried forward
- ambiguous or underspecified instructions
- reuse of probabilistic outputs as factual inputs
- Context Contamination with mixed-quality generations
Without governance, long-running sessions degrade in reliability and drift rather than converge. This is not a model failure — it is an interaction failure. The model is behaving exactly as designed. The problem is that no one is governing the interaction.
This distinction matters because it changes where the solution lives. You cannot patch your way to reliable AI outputs by switching models or tuning prompts. The variability is structural. The governance has to be structural too.
Entropy at the interaction level¶
The framework operates above the model layer — at the interaction layer, where uncertainty accumulates across turns. What it governs is Interaction-Level Entropy: the accumulation of uncertainty introduced when probabilistic outputs are reused, referenced, summarized, or implicitly promoted across user turns without explicit validation.
Token-level entropy is a property of the model. Interaction-level entropy is a property of the session — and it is entirely within the operator's control. Every time an unvalidated output gets treated as fact, every time a rejected draft stays in context, every time a retry builds on a contaminated prior turn, interaction-level entropy grows. The framework provides the mechanisms to stop that growth at every step.
Common interaction-level entropy amplifiers¶
| Behavior | Explanation |
|---|---|
| Implicit acceptance | Outputs treated as authoritative without explicit Acceptance |
| Contaminated retries | Retries build on prior probabilistic outputs rather than clean instructions |
| Context contamination | Rejected or exploratory content remains in scope and influences generation |
| Inferred structure | Scope or intent is assumed rather than declared, creating silent ambiguity |
Unchecked accumulation erodes repeatability, auditability, and epistemic clarity — even when individual outputs appear correct. A session can look fine while drifting significantly from governed intent. The framework makes that drift visible and stoppable.
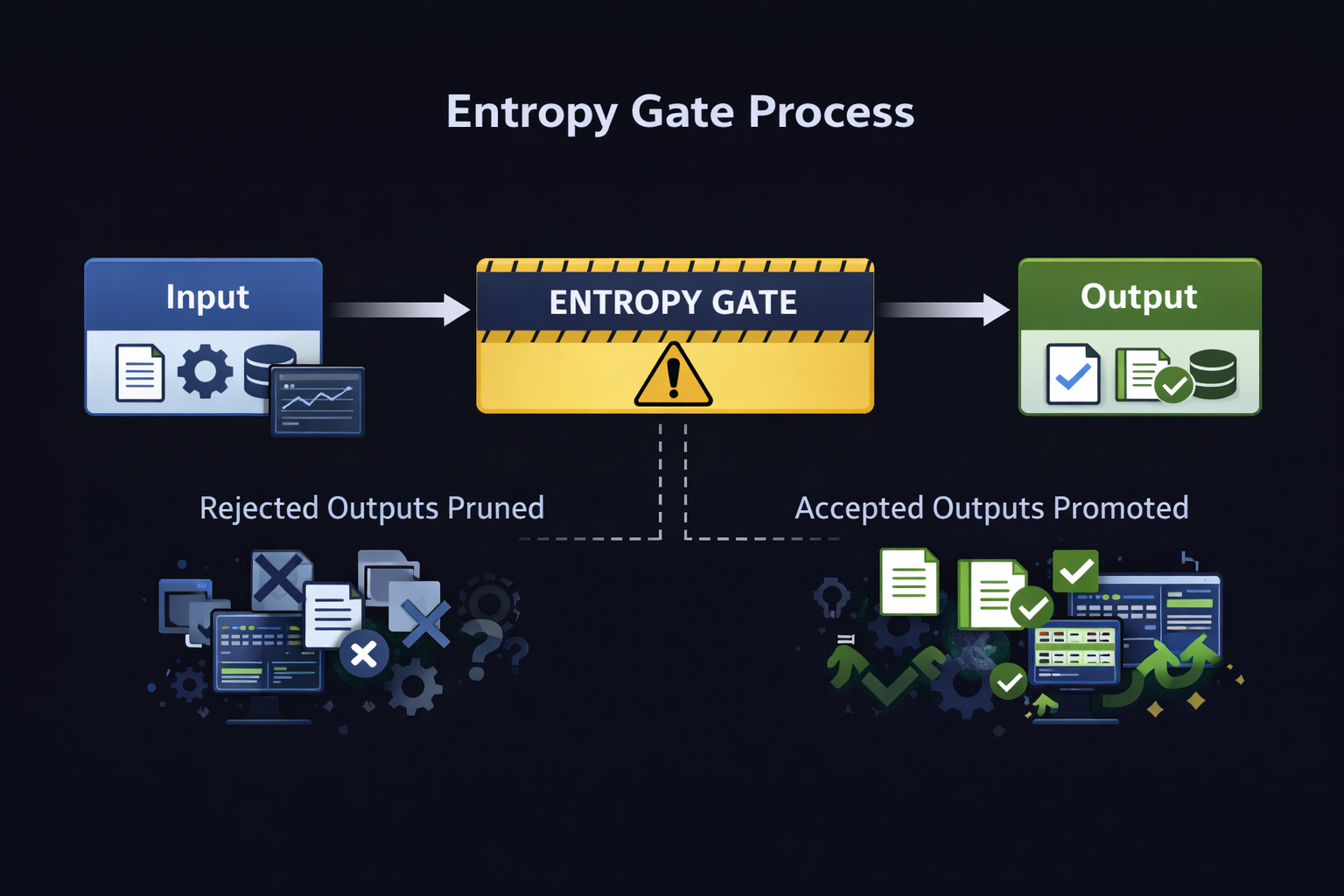
Entropy Gate Process — rejected outputs are pruned, accepted outputs are promoted
Why "Entropy-Gated" is technically correct¶
Entropy is a structural property of probabilistic systems — it cannot be removed, only governed. The framework implements Entropy Gating: a Governance mechanism that regulates precisely when and how probabilistic outputs may influence accepted state.
The gate is not a filter applied to model outputs. It is a procedural control applied to the interaction itself. Every output that passes through the gate must be explicitly disposed of by ROLE_USER before it can influence anything downstream. Outputs that are rejected are pruned — removed from context entirely, not just ignored. Outputs that are accepted are stamped with an auditable token and promoted to authoritative state. Nothing moves forward implicitly.
The result is quasi-deterministic behavior: consistent, repeatable, auditable outcomes from a system that is inherently non-deterministic. The model's probabilistic nature is preserved. The interaction's integrity is enforced.
Entropy gating mechanisms¶
| Mechanism | Purpose |
|---|---|
| Acceptance Boundary | Every output is non-authoritative until explicitly accepted — preventing silent state promotion |
| Pruning | Rejected outputs are architecturally removed from context — not ignored, deleted |
| Retry isolation | Every retry originates from a clean, edited instruction — not from prior probabilistic output |
| Role separation | All authority over acceptance, rejection, and scope belongs to ROLE_USER — the model has none |
| Process declaration | Every session declares its execution mode upfront — defining exactly how entropy is permitted to flow |
Entropy is regulated at the interaction layer. The model layer is left exactly as the provider designed it.
Threat Model: Interaction-Level Entropy¶
This threat model addresses risks arising from uncontrolled propagation of uncertainty across governed interactions involving Probabilistic Reasoning.
The threat arises from normal human behavior interacting with non-deterministic systems — no malicious actor required. A developer who retries without pruning, a reviewer who accepts an output without validating it, an operator who lets a session run long without checking for scope drift — these are the threat vectors. They are behavioral, not technical. And they are entirely preventable through governance discipline.
The framework treats this threat class with the same rigor that cybersecurity frameworks apply to configuration drift, privilege escalation, and uncontrolled state change — because the failure modes are structurally identical.
STRIDE-aligned threat classification (interaction-level)¶
STRIDE provides a structured lens for classifying governance failures at the interaction level. Each category maps to a concrete failure mode that the framework addresses through its governance mechanisms.
STRIDE mapping table¶
| STRIDE Category | Interaction-Level Interpretation | Example Failure Mode | Primary Mitigations |
|---|---|---|---|
| Spoofing | Assistant assumes authority | Authority Erosion | Role separation, refusal |
| Tampering | Implicit state modification | Implicit State Promotion | Acceptance boundary, pruning |
| Repudiation | Loss of acceptance traceability | No auditable acceptance record | Explicit acceptance stamps |
| Information Disclosure | Unvalidated output treated as fact | Epistemic leakage into downstream reasoning | Validation before acceptance |
| Denial of Service | Entropy prevents convergence | Unresolvable retry loops | Bounded execution modes, hysteresis halt |
| Elevation of Privilege | Probabilistic reasoning gains authority | Unconstrained scope expansion | OIL_CONTRACT enforcement |
Alignment with NIST and AI risk frameworks¶
The framework's governance model maps directly to established standards in cybersecurity, software development, and AI risk management. These alignments are structural — they reflect the same underlying principles of explicit authority, controlled change, and auditable state.
NIST SP 800-53 Rev. 5 (selected families)¶
| Control Family | Framework Alignment | Explanation |
|---|---|---|
| AC | Authority boundaries | Only ROLE_USER may accept or promote state |
| AU | Auditability | Acceptance and rejection events are explicit and stamped |
| CM | Configuration management | Baseline vs current artifacts prevent drift |
| PL | Planning | Hub planning separated from Lab execution |
| RA | Risk assessment | Interaction-level entropy is named and treated as operational risk |
| SI | System integrity | Pruning and retry isolation preserve session integrity |
NIST Secure Software Development Framework (SSDF)¶
| SSDF Practice | Framework Alignment | Explanation |
|---|---|---|
| PO.1 | Governance before execution | Rules, roles, and constraints defined before any execution occurs |
| PO.3 | Risk identification | Probabilistic reasoning risk is explicitly named and bounded |
| PS.3 | No reuse of rejected outputs | Rejected outputs carry zero authority and are architecturally removed |
| PW.4 | Controlled retries | Every retry requires pruning — no contaminated retry permitted |
| RV.1 | Validation precedes acceptance | Acceptance is always explicit — outputs are non-authoritative by default |
| RV.2 | Constraint-based evaluation | Every output is evaluated against declared scope and constraints |
NIST AI Risk Management Framework (AI RMF)¶
| AI RMF Function | Framework Alignment | Explanation |
|---|---|---|
| GOVERN | Human authority | Role clarity and accountability enforced through the OIL_CONTRACT |
| MAP | Risk definition | Interaction-level entropy named, classified, and bounded |
| MEASURE | Risk detection | Acceptance, rejection, and pruning events provide measurable governance signals |
| MANAGE | Risk containment | Procedural entropy gating prevents uncontrolled uncertainty accumulation |
Bottom line¶
Probabilistic systems do not fail because they are uncertain.
They fail because uncertainty is allowed to propagate unchecked.
Interaction-Level Entropy is operational, observable, and governable. Every mechanism in this framework — the OIL_CONTRACT, the INVOKER, the disposition protocol, the pruning rules, the process modes — exists to govern exactly one thing: when and how uncertainty is permitted to influence the session. That is what entropy gating means. That is what this framework delivers.